
Publications
(Google Scholar)

....[2 Min video], [Full-video] and [Poster]....
Mehdi Bahrami, Wei-Peng Chen, Lei Liu, and Mukul Prasad, "BERT-Sort: A Zero-shot MLM Semantic Encoder on Ordinal Features for AutoML" First Conference on Automated Machine Learning (Main Track). AutoML 2022 (co-located ICML). ![]() PDF
PDF  GitHub
GitHub
 BERT-Sort is highlighted in MIT Technology review: "Automated techniques could make it easier to develop AI" by Tammy Xu on Aug 5, 2022.
BERT-Sort is highlighted in MIT Technology review: "Automated techniques could make it easier to develop AI" by Tammy Xu on Aug 5, 2022.

Lei Liu, Wei-Peng Chen, Mehdi Bahrami, "Automatic Generation of Visualizations from Synthesizing Rules for Machine Learning Pipelines", 37th IEEE/ACM International Conference on Automated Software Engineering (ASE '22), October 10--14, 2022, Ann Arbor, Michigan, United States (![]() PDF:Te be added - URL).
PDF:Te be added - URL).

Mehdi Assefi, Mehdi Bahrami, Sarthak Arora, Thiab R. Taha, Hamid R. Arabnia, Khaled M. Rasheed, and Wei-Peng Chen. "An Intelligent Data-Centric Web Crawler Service for API Corpus Construction at Scale.", 2022 IEEE International Conference on Web Services (ICWS'22), July 2022, Barcelona, Spain (![]() PDF).
PDF).

Vardaan Pahuja,Yu Gu,Wenhu Chen,Mehdi Bahrami,Lei Liu,Wei-Peng Chen and Yu Su, “A Systematic Investigation of KB-Text Embedding Alignment at Scale”, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), ACL 2021 ![]() PDF GitHub
PDF GitHub
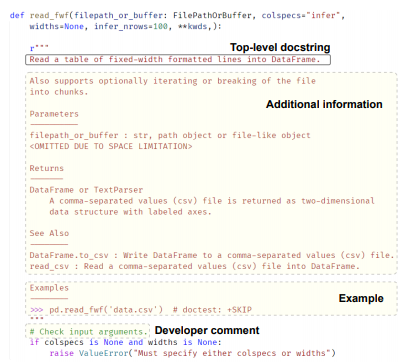
Mehdi Bahrami, N. C. Shrikanth, Shade Ruangwan, Lei Liu, Yuji Mizobuchi, Masahiro Fukuyori, Wei-Peng Chen, Kazuki Munakata, and Tim Menzies. "PyTorrent: A Python Library Corpus for Large-scale Language Models." arXiv preprint arXiv:2110.01710 (2021) ![]() PDF GitHub
PDF GitHub  Model
Model
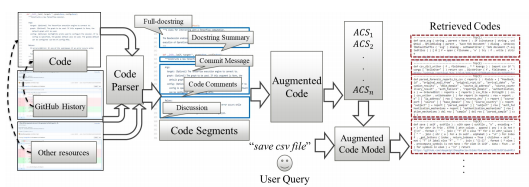
Mehdi Bahrami, N. C. Shrikanth, Yuji Mizobuchi, Lei Liu, Masahiro Fukuyori, Wei-Peng Chen, and Kazuki Munakata. "AugmentedCode: Examining the Effects of Natural Language Resources in Code Retrieval Models." arXiv preprint arXiv:2110.08512 (2021) ![]() PDF Model
PDF Model
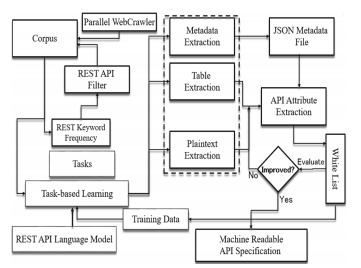
Mehdi Bahrami, and Wei-Peng Chen. "Automated Web Service Specification Generation Through a Transformation-Based Learning." International Conference on Services Computing. Springer, 2020. (![]() PDF)
PDF)
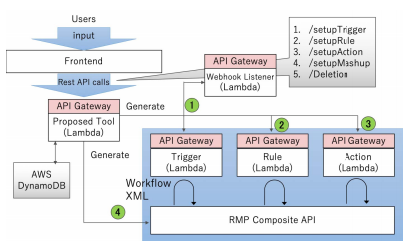
Lei Liu, Mehdi Bahrami, Wei-Peng Chen, "Automatic Generation of IFTTT Mashup Infrastructures", 2020 35th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2020. (![]() PDF)
PDF)

Liu, Lei, Mehdi Bahrami, Junhee Park, and Wei-Peng Chen. "Web API Search: Discover Web API and Its Endpoint with Natural Language Queries." In International Conference on Web Services, pp. 96-113. Springer, Cham, 2020. (![]() PDF)
PDF)
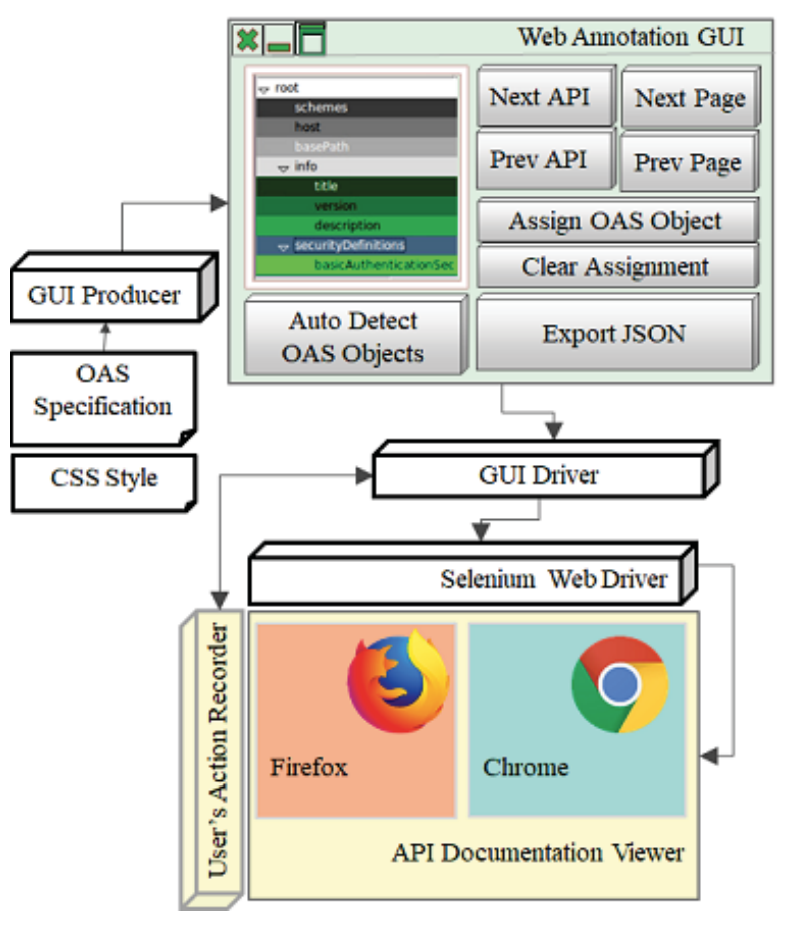
Mehdi Bahrami, and Wei-Peng Chen. "WATAPI: Composing Web API Specification from API Documentations through an Intelligent and Interactive Annotation Tool." 2019 IEEE International Conference on Big Data (Big Data). IEEE, 2019.(![]() PDF)
PDF)
![]()
Shridhar Choudhary, Ian Thomas, Mehdi Bahrami, Motoshi Sumioka "Accelerating the Digital Transformation of Business and Society Through Composite Business Ecosystem" International Conference on Advanced Information Networking and Applications. Springer, 2019. (![]() PDF)
PDF)

Mehdi Bahrami, Junhee Park, Lei Liu, Wei-Peng Chen. 2018. API Learning: Applying Machine Learning to Manage the Rise of API Economy. In WWW ’18 Companion: The 2018 Web Conference Companion, April 23–27, 2018, Lyon, France. ACM. (![]() PDF,
PDF,  Demonstration Video)
Demonstration Video)
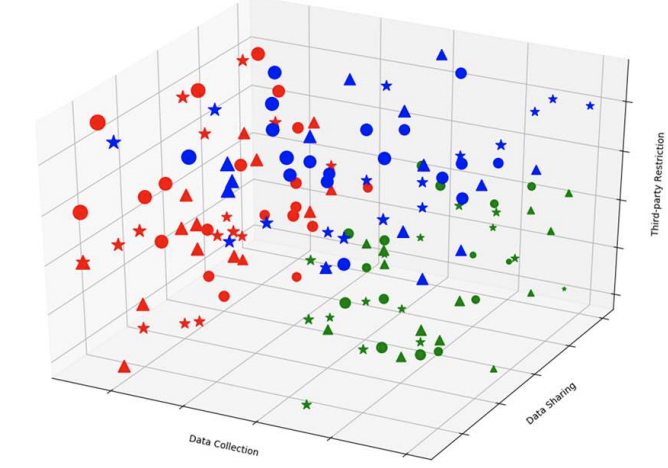
Mehdi Bahrami, Mukesh Singhal, Wei-Peng Chen, "Learning Data Privacy and Terms of Service from Different Cloud Service Providers", IEEE International Conference on Smart Cloud (IEEE SmartCloud 2017), Columbia University, New York, USA (![]() PDF)
PDF)
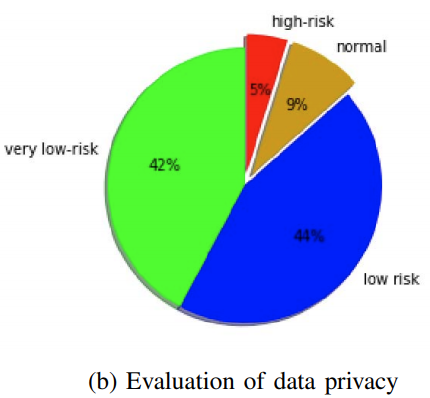
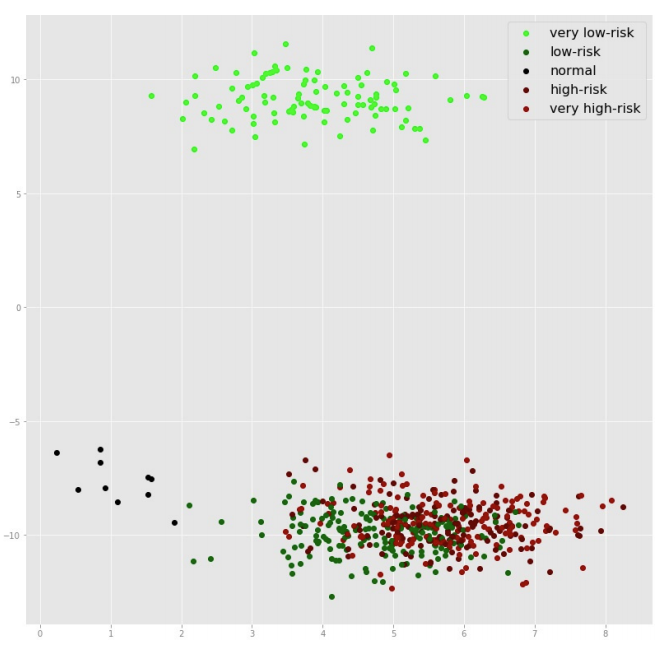
Karan K. Budhraja, Abhishek Malvankary, Mehdi Bahrami, Chinmay Kundu, Ashish Kundu, Mukesh Singhal, "Risk-Based Packet Routing for Privacy and Compliance-Preserving SDN",10th IEEE International Conference on Cloud Computing (IEEE CLOUD 2017), Honolulu, Hawaii, USA (![]() PDF)
PDF)
A Dynamic Cloud with Data Privacy Preservation, Ph.D. Dissertation
by Mehdi Bahrami
Bahrami, Mehdi. (2016). A Dynamic Cloud with Data Privacy Preservation. UC Merced: Electrical Engineering and Computer Science. Retrieved from: http://escholarship.org/uc/item/03g6171c ( Download PDF - Endnote ).
Download PDF - Endnote ).
An Efficient Parallel Implementation of a Light-weight Data Privacy Method for Mobile Cloud Users
by Mehdi Bahrami, Dong Li, Mukesh Singhal and Ashish Kundu
Abstract. Cloud computing provides an opportunity to users to outsource their data and applications. However, data privacy is one of the key challenges for the users who are outsourcing data on some transparent cloud servers. Data encryption is the best option to protect users’ data privacy on the cloud. However, computation overheads of encryption methods could be expensive to some small computing machines, such as mobile or IoT devices with limited resources, such as battery. In our previous study, we developed a light-weight Data Privacy Method (DPM) based on a chaos system that uses a Pseudo Random Permutation (PRP) to scramble the content of original data. Although the nature of PRP is against parallelization, we provide an efficient parallel algorithm to scramble a file while the file splits into multiple chunks. The parallel DPM avoids an adversary to access the original data (e.g., by using a brute-force attack), when the size of each scrambled data is large enough. In this paper, we accelerate DPM on a Graphic Processing Unit (GPU) by using NVIDIA CUDA platform for implementation. We assess the generated shuffle addresses from pseudo-random and the distribution of randomness when the computation on data is parallelized on a multiple GPU-cores. A set of rigorous evaluation results shows that the parallel DPM provides a superior performance over tradition DPM when the most time consuming of native CUDA parallel functions have monitored. We also perform a security analysis of parallel DPM to ensure it is secure and it is a cost effective model to protect users’ data privacy in a cloud environment.
Keywords: GPU; Cloud Computing; Parallel Computing; Data Privacy; Cloud Privacy;
Citation: Mehdi Bahrami, Dong Li, Mukesh Singhal, Ashish Kundu, "An Efficient Parallel Implementation of a Light-weight Data Privacy Method for Mobile Cloud Users", ACM/IEEE SIGHPC SC-DataCloud 2016, Salt Lake City, Utah, Nov 2016. ( Download PDF).
CloudPDB: A Light-weight Data Privacy Schema for Cloud-based Databases
by Mehdi Bahrami and Mukesh Singhal
Abstract. Cloud computing paradigm offers an opportunity to in-house IT departments to establish their services on the cloud with minimum investment, and lower maintenance cost. This opportunity includes database services that allow a massive amount of data to be stored on the cloud. However, outsourcing data to the cloud may expose users' data to the cloud vendor, or the vendors' partners. Encryption methods, such as AES can be used to protect users' data privacy. Although the secure methods protect data against the untrusted cloud vendor, or an adversary, the security methods add additional computation overheads. In this paper, we proposed a light-weight data privacy schema for cloud based databases (CloudPDB) that scrambles data on each selected bucket (multiple records, or fields) of a database. The proposed schema uses a pre-defined database of a chaos system to store data on the cloud that protect data against an adversary inside or outside of an untrusted cloud vendor. We implemented the proposed schema on a well-known standard database benchmark, TPC-H with different query sizes. We ran several queries to assess the performance of the proposed schema. The evaluation shows that the proposed schema provides a better performance over other well-known encryption methods. In addition, we assess the security level of the proposed schema.
Citation (Acceptance Rate: 30%):
Mehdi Bahrami and Mukesh Singhal, "CloudPDB: A Light-weight Data Privacy Schema for Cloud-based Databases", 2016 IEEE International Conference on Computing, Networking and Communications, Cloud Computing and Big Data, Kauai, Hawaii, Feb 2016.
(![]() Download PDF)
Download PDF)
A Dynamic Cloud Computing Platform for eHealth Systems
by Mehdi Bahrami and Mukesh Singhal
Abstract. Cloud Computing technology offers new opportunities for outsourcing data, and outsourcing computation to individuals, start-up businesses, and corporations in health care. Although cloud computing paradigm provides interesting, and cost effective opportunities to the users, it is not mature, and using the cloud introduces new obstacles to users. For instance, vendor lock-in issue that causes a healthcare system rely on a cloud vendor infrastructure, and it does not allow the system to easily transit from one vendor to another. Cloud data privacy is another issue and data privacy could be violated due to outsourcing data to a cloud computing system, in particular for a healthcare system that archives and processes sensitive data. In this paper, we present a novel cloud computing platform based on a Service-Oriented cloud architecture. The proposed platform can be ran on the top of heterogeneous cloud computing systems that provides standard, dynamic and customizable services for eHealth systems. The proposed platform allows heterogeneous clouds provide a uniform service interface for eHealth systems that enable users to freely transfer their data and application from one vendor to another with minimal modifications. We implement the proposed platform for an eHealth system that maintains patients' data privacy in the cloud. We consider a data accessibility scenario with implementing two methods, AES and a light-weight data privacy method to protect patients' data privacy on the proposed platform. We assess the performance and the scalability of the implemented platform for a massive electronic medical record. The experimental results show that the proposed platform have not introduce additional overheads when we run data privacy protection methods on the proposed platform.
Citation (To appear):
Mehdi Bahrami and Mukesh Singhal, "A Dynamic Cloud Computing Platform for eHealth Systems" in Proceedings of 17th IEEE Int. Conference on E-Health Networking, Applications and Services (Healthcom’15), Oct 14-17, Boston, MA, USA, IEEE, 2015.
(![]() Download PDF)
Download PDF)
DCCSOA: A Dynamic Cloud Computing Service-Oriented Architecture
by Mehdi Bahrami and Mukesh Singhal
Abstract. The emerging field of Cloud Computing provides several advantages over traditional in-house IT services, such as accessing to elastic on-demand computing and storage over the Internet, and cost effective pay-per-use subscription plans. However, according to the International Data Corporation (IDC), cloud computing has several issues, such as a lack of standardization, a lack of customization, and limited interoperability. In addition, there is an increasing demand for introduction and migration of a variety of services to cloud computing systems, which are abstract their offering services into various *-as-a-Services (*aaS) layers. Although each such service provides a new feature (e.g., simulation services in cloud), it aggravates the issues due to the lack of standardization and inability to customize services by a vendor because each *aaS has its own features, requirements and output. In this paper, we propose a cloud architecture to alleviate issues associated with standardization and customization. In the cloud, the proposed architecture uses a single layer, called Template-as-a-Service (TaaS), to provide: (i) a single service layer for interaction with all resources and major cloud services (e.g., IaaS, PaaS, SaaS and *aaS), (ii) a standardization for existing services and future *aaS across different cloud environments, and (iii) a customizable architecture which can be modified on demand by a cloud vendor, and its partners to provide the flexibility on cloud computing systems. A comparison with previous studies show that the proposed architecture provides customization and standardization for cloud services with minimum modifications.
Citation: (Acceptance Rate: 25.6%)
Mehdi Bahrami and Mukesh Singhal, "DCCSOA: A Dynamic Cloud Computing Service-Oriented Architecture" in 16th IEEE International Conference on Information Reuse and Integration (IEEE IRI 2015), Aug 13-17, San Francisco, IEEE, 2015.
(![]() Download PDF)
Download PDF)
A Light-Weight Permutation based Method for Data Privacy in Mobile Cloud Computing
by Mehdi Bahrami and Mukesh Singhal
Abstract. Cloud computing paradigm provides virtual IT infrastructures with a set of resources that are shared with multi-tenant users. Data Privacy is one of the major challenges when users outsource their data to a cloud computing system. Privacy can be violated by the cloud vendor, vendor’s authorized users, other cloud users, unauthorized users, or external malicious entities. Encryption is one of the solutions to protect and maintain privacy of cloud-stored data. However, encryption methods are complex and expensive for mobile devices. In this paper, we propose a new light-weight method for mobile clients to store data on one or multiple clouds by using pseudo-random permutation based on chaos systems. The proposed method can be used in the client mobile devices to store data in the cloud(s) without using cloud computing resources for encryption to maintain user’s privacy. We consider JPEG image format as a case study to present and evaluate the proposed method. Our experimental results show that the proposed method achieve superior performance compared to over encryption methods, such as AES and encryption on JPEG encoders while protecting the mobile user data privacy. We review major security attack scenarios against the proposed method that shows the level of security.
Citation:
Mehdi Bahrami and Mukesh Singhal, "A Light-Weight Permutation based Method for Data Privacy in Mobile Cloud Computing" in 2015 3rd IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (IEEE Mobile Cloud 2015) San Francisco, IEEE, 2015.
(![]() Download PDF)
Download PDF)
A Cloud-based Web Crawler Architecture
by Mehdi Bahrami, Mukesh Singhal and Zixuan Zhuang
Abstract. Web crawlers work on the behalf of applications or services to find interesting and related information on the web. For example, search engines use web crawlers to index the Internet. Web crawlers have several challenges, such as complexity between links and highly intensive computation requirements when a web crawler wants to retrieve complex connected links. Another issue is the storage of a massive amount of indexed links or downloaded unstructured data, such as binary files, videos or images. As the volume of information on the Internet increases rapidly and requests may search data in a variety of formats including unstructured data, no cloud-based architecture exists in the literatures for web crawlers that could effectively address both highly intensive computing and storage issues. The cloud computing paradigm provides support for elastic resources and unstructured data, and provides pay-peruse features that allow individual businesses to run their own web crawlers for crawling the Internet or a limited web hosts. In this paper, we propose a cloud-based web crawler architecture that uses cloud computing features and the MapReduce programming technique. The proposed web crawler allows us to crawl the web by using distributed agents and each agent stores its own finding on a Cloud Azure Table (NoSQL database). The proposed web crawler also could store unstructured and massive amount of data on Azure Blob storage. We analyze the performance and scalability of the proposed web crawler and we describe the advantages of the proposed web crawler over traditional distributed web crawlers.
Citation:
Mehdi Bahrami, Mukesh Singhal and Zixuan Zhuang, "A Cloud-based Web Crawler Architecture" in Intelligence in Next Generation Networks (ICIN), 2015 18th International Conference on , vol., no., pp.216,223, 17-19 Feb. 2015 (ICIN 2015), Paris, France, IEEE, 2015. doi: 10.1109/ICIN.2015.7073834
(![]() Download PDF/Published paper at IEEE)
Download PDF/Published paper at IEEE)
The Role of Cloud Computing Architecture in Big Data
by Mehdi Bahrami and Mukesh Singhal
Abstract. In this data-driven society, we are collecting a massive amount of data from people, actions, sensors, algorithms and the web; handling “Big Data” has become a major challenge. A question still exists regarding when data may be called big data. How large is big data? What is the correlation between big data and business intelligence? What is the optimal solution for storing, editing, retrieving, analyzing, maintaining, and recovering big data? How can cloud computing help in handling big data issues? What is the role of a cloud architecture in handling big data? How important is big data in business intelligence? This chapter attempts to answer these questions. First, we review a definition of big data. Second, we describe the important challenges of storing, analyzing, maintaining, recovering and retrieving a big data. Third, we address the role of Cloud Computing Architecture as a solution for these important issues that deal with big data. We also discuss the definition and major features of cloud computing systems. Then we explain how cloud computing can provide a solution for big data with cloud services and open-source cloud software tools for handling big data issues. Finally, we explain the role of cloud architecture in big data, the role of major cloud service layers in big data, and the role of cloud computing systems in handling big data in business intelligence models.
Citation:
Mehdi Bahrami and Mukesh Singhal, “The Role of Cloud Computing Architecture in Big Data”, Information Granularity, Big Data, and Computational Intelligence, Vol. 8, pp. 275-295, Chapter 13, Pedrycz and S.-M. Chen (eds.), Springer, 2015 http://goo.gl/4gNW3s
![]() Download Chapter| Download Book )
Download Chapter| Download Book )
Interview
Choose the Right Tools for Big Data Development, Info-Tech, Canada, 2014.


